文章概览:
1 前言
Hadoop高可用品台搭建完备后,参见《》,下一步是在集群上跑任务,本文主要讲述Eclipse远程提交hadoop集群任务。
2 Eclipse查看远程hadoop集群文件
2.1 编译hadoop eclipse 插件
Hadoop集群文件查看可以通过webUI或hadoop Cmd,为了在Eclipse上方便增删改查集群文件,我们需要编译hadoop eclipse 插件,步骤如下:
① 环境准备
JDK环境配置 配置JAVA_HOME,并将bin目录配置到path
ANT环境配置 配置ANT_HOME,并将bin目录配置到path
在cmd查看:

② 软件准备
hadoop2x-eclipse-plugin-master
hadoop-common-2.2.0-bin-master
hadoop-2.6.0
eclipse-jee-luna-SR2-win32-x86_64
③ 编译
注:软件位置为自己机器上位置,请勿照搬。
E:\>cd E:\hadoop\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin E:\hadoop\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin>ant jar -Dve
rsion=2.6.0 -Declipse.home=E:\eclipse -Dhadoop.home=E:\hadoop\hadoop-2.6.0Buildfile: E:\hadoop\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin\build.xmlcheck-contrib:init: [echo] contrib: eclipse-plugininit-contrib:ivy-probe-antlib:ivy-init-antlib:ivy-init:[ivy:configure] :: Ivy 2.1.0 - 20090925235825 :: http://ant.apache.org/ivy/ ::[ivy:configure] :: loading settings :: file = E:\hadoop\hadoop2x-eclipse-plugin-master\ivy\ivysettings.xmlivy-resolve-common:ivy-retrieve-common:[ivy:cachepath] DEPRECATED: 'ivy.conf.file' is deprecated, use 'ivy.settings.file' instead[ivy:cachepath] :: loading settings :: file = E:\hadoop\hadoop2x-eclipse-plugin-master\ivy\ivysettings.xmlcompile: [echo] contrib: eclipse-plugin [javac] E:\hadoop\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin\build.xml:76: warning: 'includeantruntime' was not set, defaulting to build.sysclasspath=last; set to false for repeatable buildsjar:BUILD SUCCESSFULTotal time: 10 seconds
成功编译,生成如下图:

④ 将改文件拷贝到Eclipse中plugins目录下,重启Eclipse会出现:

2.2 配置hadoop选项
打开Map/Reduce Locations

编辑Map/Reduce配置项:
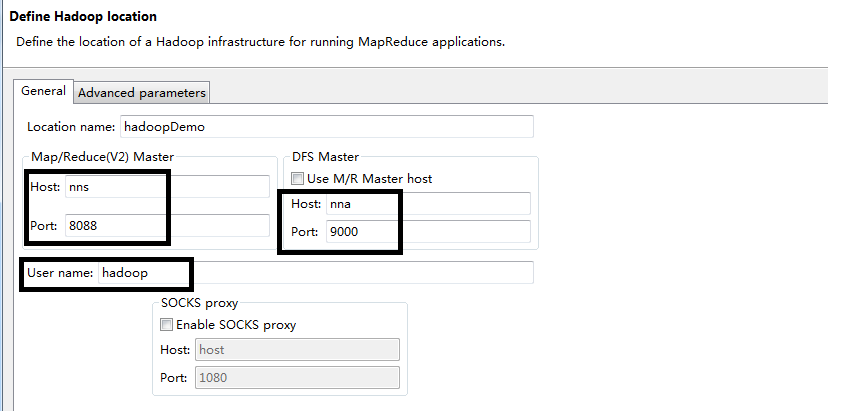
根据上一篇,我们配置用户hadoop,Active HDFS和Active NM位置信息。
完成后,就可以在Eclipse中查看HDFS文件信息:

2.3 hdfs简单实例
我们编写一个hdfs简单实例,来远程操作hadoop。
1 package com.diexun.cn.mapred; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FSDataOutputStream; 9 import org.apache.hadoop.fs.FileSystem;10 import org.apache.hadoop.fs.Path;11 12 public class MR2Test {13 14 static final String INPUT_PATH = "hdfs://192.168.137.101:9000/hello";15 static final String OUTPUT_PATH = "hdfs://192.168.137.101:9000/output";16 17 public static void main(String[] args) throws IOException, URISyntaxException {18 Configuration conf = new Configuration();19 final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);20 final Path outPath = new Path(OUTPUT_PATH);21 if (fileSystem.exists(outPath)) {22 fileSystem.delete(outPath, true);23 }24 25 FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path(INPUT_PATH));26 fsDataOutputStream.writeBytes("welcome to here ...");27 }28 29 } 用Eclipse查看HDFS文件,发现hello文件被修改为“welcome to here ...”。
3 Eclipse提交远程hadoop集群任务
正式进入本文的正题,新建一个Map/Reduce Project,会引用很多jar(注:平常我们都是新建Maven项目进行开发,有利于程序迁移及体积,后面的文章会以Maven构建),将自带WordCount实例拷贝到Eclipse,
配置运行参数:(注:填写hdfs集群上路径,本地路径无效)

执行,出现线面结果:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method) at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557) at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977) at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187) at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174) at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108) at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285) at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115) at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131) at org.apache.hadoop.mapred.LocalJobRunner$Job.(LocalJobRunner.java:163) at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:536) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314) at WordCount.main(WordCount.java:76)
方便后面打印,先添加log4j.properties文件:
log4j.rootLogger=DEBUG,stdout,R log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=mapreduce_test.log log4j.appender.R.MaxFileSize=1MB log4j.appender.R.MaxBackupIndex=1 log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n log4j.logger.com.codefutures=INFO
根据出错提示,是由于NativeIO.java中return access0(path, desiredAccess.accessRight());导致,此句注,改为返回return true。
修改源码后,在项目里创建和Apache中一样的包,此包会覆盖Apache源码包,如下:

再次执行:
INFO - Job job_local401325246_0001 completed successfullyDEBUG - PrivilegedAction as:wangxiaolong (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getCounters(Job.java:764) INFO - Counters: 38 File System Counters FILE: Number of bytes read=16290 FILE: Number of bytes written=545254 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=38132 HDFS: Number of bytes written=6834 HDFS: Number of read operations=15 HDFS: Number of large read operations=0 HDFS: Number of write operations=4 Map-Reduce Framework Map input records=174 Map output records=1139 Map output bytes=23459 Map output materialized bytes=7976 Input split bytes=99 Combine input records=1139 Combine output records=286 Reduce input groups=286 Reduce shuffle bytes=7976 Reduce input records=286 Reduce output records=286 Spilled Records=572 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=18 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=468713472 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=19066 File Output Format Counters Bytes Written=6834
确实已经成功执行了,可发现“INFO - Job job_local401325246_0001 completed successfully”,
观察http://nns:8088/cluster/apps也没有发现该任务,说明此任务并未提交到集群执行。
添加配置文件,如下:

配置文件直接从集群下载(注:集群中yarn-site.xml配置中“yarn.resourcemanager.ha.id”是有所不同的),该下载哪份配置?
由于集群中Active RM是nns,故下载nns中yarn-site.xml配置。执行:
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.diexun.cn.mapred.WordCount$TokenizerMapper not found at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2074) at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:186) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:742) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)Caused by: java.lang.ClassNotFoundException: Class com.diexun.cn.mapred.WordCount$TokenizerMapper not found at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:1980) at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2072) ... 8 more
没有找到对应的代码文件,我们把代码打包,并设置conf,conf.set("mapred.jar", "**.jar"); 再次执行:
Exception message: /bin/bash: line 0: fg: no job controlStack trace: ExitCodeException exitCode=1: /bin/bash: line 0: fg: no job control at org.apache.hadoop.util.Shell.runCommand(Shell.java:538) at org.apache.hadoop.util.Shell.run(Shell.java:455) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715) at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
出现如下错误,是由于平台引起,在hadoop2.2~2.5中需修改源码编译(略),hadoop2.6已经可以直接添加配置,conf.set("mapreduce.app-submission.cross-platform", "true");或直接到mapred-site.xml中配置。再次执行:
INFO - Job job_1438912697979_0023 completed successfullyDEBUG - PrivilegedAction as:wangxiaolong (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getCounters(Job.java:764)DEBUG - IPC Client (1894045259) connection to dn2/192.168.137.104:56327 from wangxiaolong sending #217DEBUG - IPC Client (1894045259) connection to dn2/192.168.137.104:56327 from wangxiaolong got value #217DEBUG - Call: getCounters took 139ms INFO - Counters: 49 File System Counters FILE: Number of bytes read=149 FILE: Number of bytes written=325029 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=255 HDFS: Number of bytes written=86 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=45308 Total time spent by all reduces in occupied slots (ms)=9324 Total time spent by all map tasks (ms)=45308 Total time spent by all reduce tasks (ms)=9324 Total vcore-seconds taken by all map tasks=45308 Total vcore-seconds taken by all reduce tasks=9324 Total megabyte-seconds taken by all map tasks=46395392 Total megabyte-seconds taken by all reduce tasks=9547776 Map-Reduce Framework Map input records=3 Map output records=12 Map output bytes=119 Map output materialized bytes=155 Input split bytes=184 Combine input records=12 Combine output records=12 Reduce input groups=11 Reduce shuffle bytes=155 Reduce input records=12 Reduce output records=11 Spilled Records=24 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=827 CPU time spent (ms)=4130 Physical memory (bytes) snapshot=479911936 Virtual memory (bytes) snapshot=6192558080 Total committed heap usage (bytes)=261115904 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=71 File Output Format Counters Bytes Written=86
至此,任务已经成功提交至集群执行。
有时我们想用我们特定用户去执行任务(注:dfs.permissions.enabled为true时,往往会涉及用户权限问题),可以在VM arguments中设置,这样任务的提交这就变成了设定者。

4 小结
本文主要阐述hadoop eclipse插件的编译与远程提交hadoop集群任务。hadoop eclipse插件的编译需要注意软件安装位置对应。远程提交hadoop集群任务需留意,本地与HDFS文件路径异同,加载特定文件配置,指定特定用户,跨平台异常等问题。
参考: